The Hidden Work Behind Reliable Address Data
People are often surprised to learn how much time and effort Regio puts into maintaining address data across Estonia, Latvia and Lithuania. After all, addresses are assigned and maintained by public institutions, and much of the source data is openly available. Why, then, is so much additional work needed?
This was the subject of Regio’s presentation at BalticGIT 2026: “Beyond Points on a Map: Maintaining Address Intelligence Across the Baltics.”

The invisible infrastructure behind everyday services
People rarely think about address data when it works. Its importance becomes visible when an address cannot be entered into an online form, found on a map or in a navigation system, or when a delivery fails to reach the correct destination.
A smooth user experience usually depends on considerable work behind the scenes.
Organizations use address data for far more than displaying locations on a map. It supports deliveries, navigation, address and place search, customer-data management, map services, planning and spatial analysis. In each case, the service may appear simple while relying on a complex combination of source data, rules and spatial relationships.’
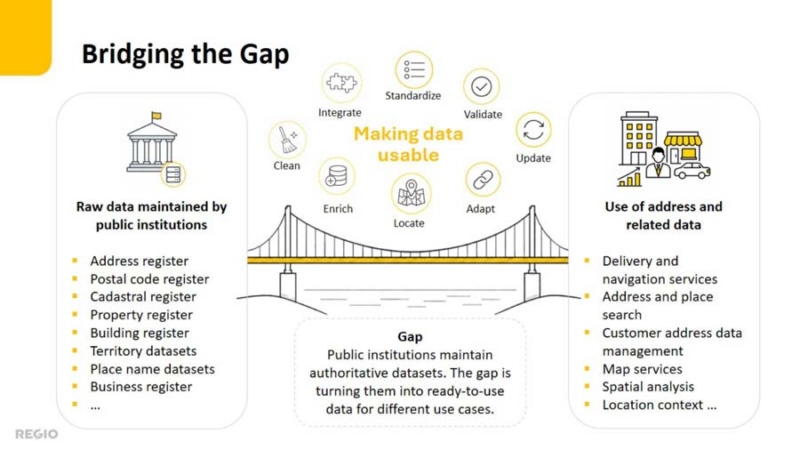
Bridging the gap between registers and services
Public institutions maintain authoritative datasets such as address registers, postal code, cadastral and property information, buildings, administrative areas and place names data. Each has been created for a particular purpose and may differ in format, structure, identifiers, quality, coverage and update cycle. Related sources may also describe the same objects differently or fall out of sync.
This creates a gap between official source data and the consistent, reliable information required by end-user services. Bridging it requires more than transferring datasets into a common database: the data must be interpreted, integrated, standardized, validated, spatially refined, connected to related information and continuously updated.
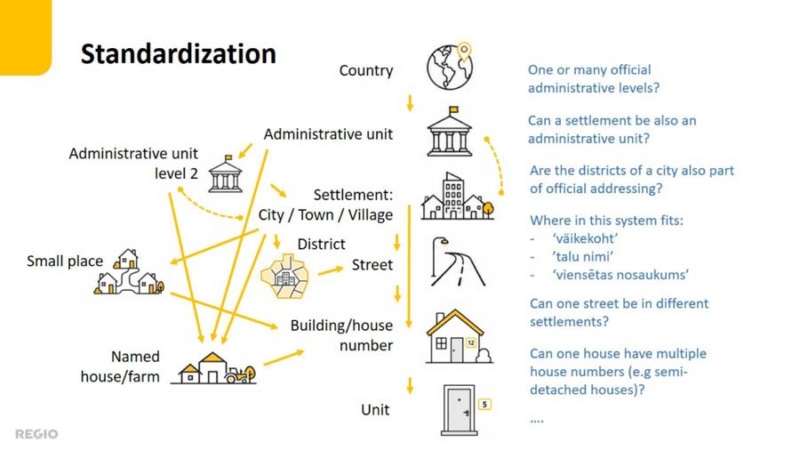
Standardizing without losing national meaning
At first glance, an address hierarchy may seem straightforward:
country > administrative layer > settlement > street > building > unit.
But the closer we look, the more questions arise, especially when different countries are placed side by side.
How many administrative levels should an address contain? Can a settlement also be an administrative unit? Can one street cross several settlements? Where do Estonia’s talu, or väikekoht or Latvia’s viensēta fit in the hierarchy? How should Lithuanian house numbers without a street or Latvian house names without a settlement reference be handled? And that is only the beginning.
Estonia offers a good example. Following the latest administrative reform, some municipalities were named after a city while extending far beyond the urban settlement itself. This has produced addresses such as “Läänemaa, Haapsalu linn, Kiideva küla”, where a village seems to be located within a city. Even stranger is “Läänemaa, Haapsalu linn, Haapsalu linn”, where the same name appears twice: first as the municipality and then as the settlement. The structure is officially correct, but it is hardly a natural way to present an address to someone searching for a place or planning a route.
A common Baltic address data model must therefore preserve the official meaning and national structure of Estonian, Latvian and Lithuanian addresses while presenting them in one consistent and understandable form.

One address, multiple geometries
An address is often imagined as a single point on a map. In practice, different uses require different spatial representations.
The official register point may lie in the centre of a cadastral parcel, while a map or delivery service needs a point close to the building entrance. Navigation systems also need an access point on the road network: the place from which the address can actually be reached. This is not always the nearest point on the nearest road. A river, railway, fence or another barrier may stand in between, so identifying the correct access point requires an understanding of the surrounding geography, not merely a distance calculation.
Most address objects also need an area representation alongside the point. For countries, administrative units, settlements and smaller localities, these areas follow territorial boundaries. At building-address level, an appropriate area may be derived from cadastral parcels or relevant parts of them. The areas are important for map display, reverse geocoding, spatial analysis and determining spatial relationships between different datasets.
The main exceptions are streets, which are primarily represented as lines connected to the road network.
A complete address data model must therefore manage points, lines and areas as well as the relationships between them.

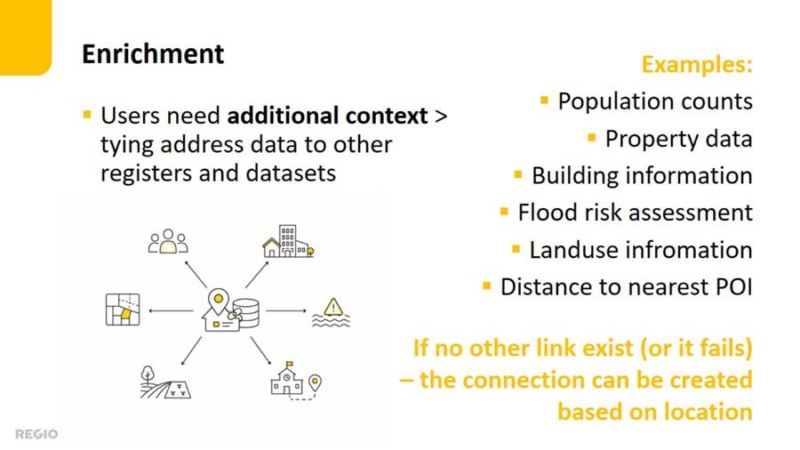
Giving addresses more meaning
Address data becomes more valuable when additional information is attached to it. An address can be enriched, for example with building or property information, population figures, land use, flood risk or distances to closest services.
Some of these links can be created using shared identifiers. In practice, however, identifiers may be missing, change over time or be used inconsistently across datasets.
When address geometries are accurate, additional information can also be attached spatially. From there, the possibilities are almost endless: virtually any information with a location can be connected to an address and made easier to search, analyse and use.
Integration requires interpretation
Combining sources inevitably reveals discrepancies. This does not necessarily mean that the source data is wrong: datasets may serve different purposes, follow different update cycles or represent the same object differently.
Integrated data must therefore be checked for completeness, consistency and spatial correctness. But finding a discrepancy is only the first step. Someone must understand why the sources differ and decide how to resolve the issue without creating new errors downstream.
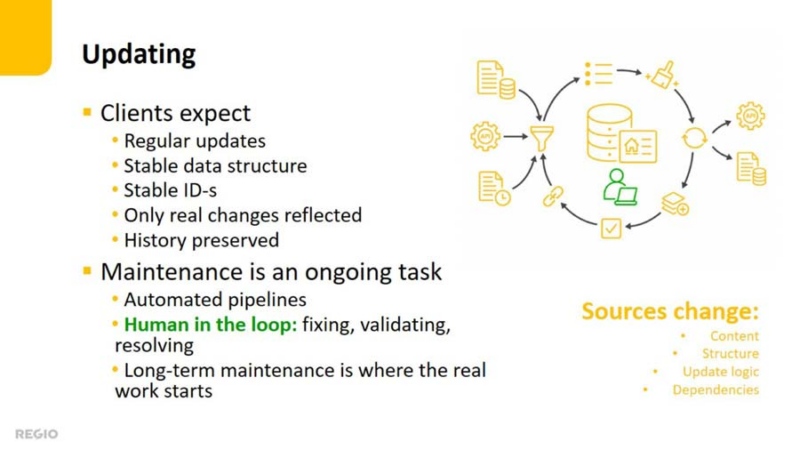
Automation is only the beginning
Much of the processing can be automated. Data pipelines can retrieve updates, transform source structures, create relationships, enrich objects and run validation tests.
But building an automated workflow is only the beginning. The real challenge is keeping it reliable as source content, formats, access methods and dependencies change.
A human-in-the-loop approach therefore remains essential. Specialists monitor results, investigate unexpected changes, resolve uncertain cases and correct problems that cannot be handled reliably through general rules.
Long-term maintenance is where much of the real work begins.
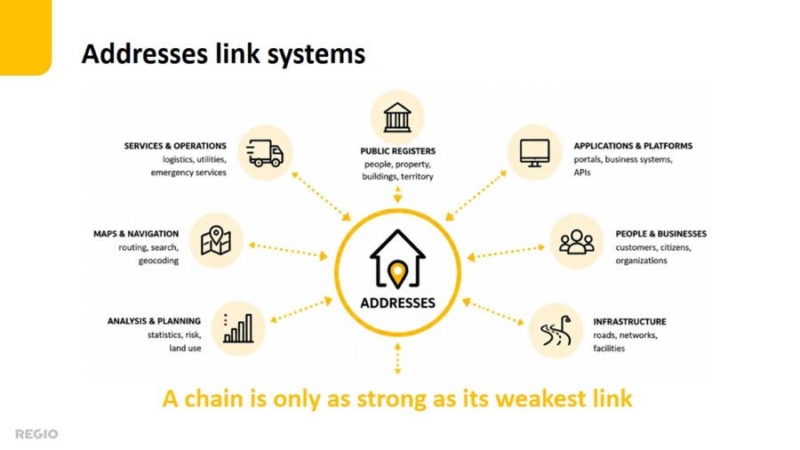
Addresses as the connecting link
Addresses link buildings, roads, properties, businesses, services, territories and people. In many systems, they provide the common reference needed to connect otherwise separate datasets.
If address data is incomplete, inaccurate or outdated, the effects spread to navigation, deliveries, search, analysis and other services that rely on it. Maintaining reliable address data therefore requires continuous standardization, spatial correction, linking, validation and monitoring.
This is why Regio invests so much effort in address data maintenance: not simply to reproduce official records, but to turn them into consistent, usable and dependable information for the services that rely on them.
 Püü Polma
Püü Polma
